Isolating a Distribution’s Subset
In my Joint Distributions article, I illustrated how to provide a data set using two (joint) distributions, with the Age Groups and Years distributions complementing each other.
In this article I will demonstrate how to create a marginal distribution, which isolates one of the available distributions and measures it against the total values for that distribution.
I’ll begin with the same Age Groups and Years distributions from the former article.
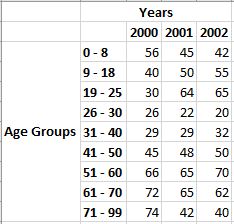
Marginal Distribution for Age Groups
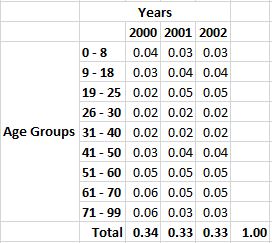
First, I’ll produce a total value for the first age group.
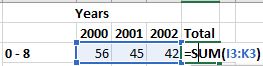

Now, I’ll replicate the formula to all age groups.
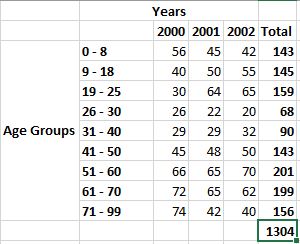
With a total value for each age group and grand total for all age groups, I’m ready to produce a marginal distribution which compares one distribution’s values against the grand total for all distributions’ values.
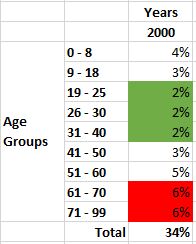
First, I’ll convert each age group’s values to percentages by comparing it against the grant total.

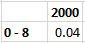
Now, I’ll replicate that formula to all other age group cells.

Finally, I’ll convert all values to percentages.
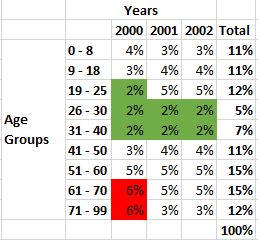
With all values converted, I’ve highlighted the lowest and highest values in the age groups.
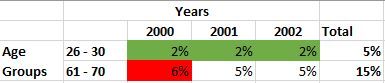
Now, I am able to isolate just those age groups to see 26-30 contains the lowest values and the age group 61-70, the highest values. Each age group represents a marginal distribution.
Marginal Distribution for Years
Now, I’ll repeat the previous steps to isolate the year with the highest values.
First, I’ll produce total values for each year, then a grand total for all years.
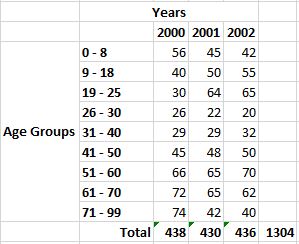
Next, I’ll convert the values into percentages.
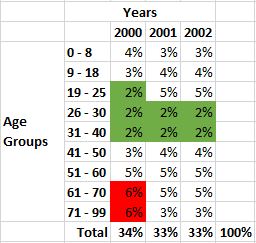
With each year’s percentage dipslayed when compared with the total, I’m now able to isolate the year with the highest values. Year 2000 represents a marginal distribution.