Arranging Database Tables to Support Rich, Effective Analysis
In traditional systems used for e-commerce or other common input/edit systems commonly referred to as online transactional processing (OLTP), there should be no instances of duplicate data, for OLAP the opposite is true.
For OLTP systems the focus is on the fastest method of providing high-volume additions and changes to data.
However, when complex and rapid analysis is required for business strategy, data being analyzed isn’t rapidly changing, but undergoing extensive analysis, desiring to discern trends.
Therefore when online analytical processing (OLAP) is necessary, data for reporting is duplicated as needed, thus, reducing the time needed to retrieve and display necessary data points analyzed.
To support OLAP analysis, two ways of arranging the data, or schemas, are used – star and snowflake.
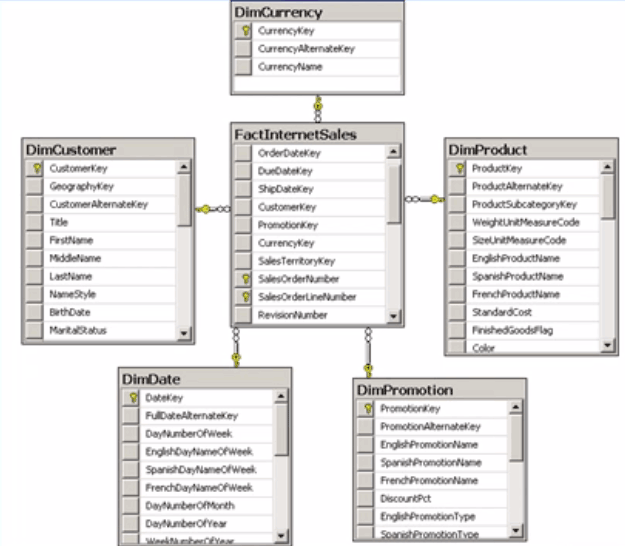
A Star schema is the most common used and leverages one fact table containing measures to analyze such as order quantity or sales amount. These fact tables also contain a key which links to dimension tables which define the facts such as customers, employees, and stores.
As you can see in the example below, the “facts” represent internet sales, each of which is represented by a key linking back to its dimension table explaining that fact.
Snowflake schemas on the other hand contain multiple dimension tables joined together and only one of them joined to fact table. For example, in a snowflake schema a product table would have a category table joined to it, but only the product table would be joined to the fact table. This arrangement of tables degrades performance for those queries being executed during analysis.
